
お知らせ
2023.12.5(Tue)




目次
こんにちわ。井上です。
現在開発しているシステムではビッグデータを扱っています。
そのデータを統計分析することで、未来のデータを予測したいと考えています。
そのためにはどのような言語を使って、どうやって処理していけばいいのか検討もつきません。
そこで今回は、どのようにすればシステムでビッグデータを利用して、統計分析できるのかを模索していこうと思います。
特に決まった定義がないようなので、今回は以下の2つを定義とします。
事業に役立つ知見を導出するためのデータ
市販されているデータベース管理ツールや従来のデータ処理アプリケーションで処理することが困難なほど巨大で複雑なデータ集合の集積物を表す用語
どちらにもいえることは、データ数が何件以上とか、何GB以上などのデータとしての大きさは決まりがないようです。
今あるデータを活用して未来に役立てようということで進めていきたいと思います。
統計分析で調べると、以下の2つが候補として上がりました。
R言語
R言語は、オープンソース・フリーソフトウェアの統計解析向けのプログラミング言語及びその開発環境である
R言語は汎用のプログラミング言語とは異なり、統計解析やデータ解析に特化している言語となります。
自分の知っているプログラミングとは少し違うようで、ちょっと癖がありそうです。
Python
汎用のプログラミング言語として設計されており、標準ライブラリやサードパーティ製のライブラリも充実している。
そのためPythonはWebアプリケーションやデスクトップアプリケーションなどの開発はもとより、システム用のスクリプトや、
各種の自動処理、理工学や統計解析のためのツールとしてなど、幅広い領域で使用されている。
Pythonはいたって普通の汎用的なプログラミング言語ですが、数値計算や統計処理をするライブラリがあるのでデータ処理をするのに有効です。
プログラムを書く際のルールが厳格に定義されているので、誰が書いてもほぼ同じになるという特徴があります。
いろいろと考えた結果、今回はPythonを使ってデータ処理をしていきたいと思います。
(PythonのディストリビューションであるAnacondaを使用します。AnacondaはPython本体にデータ分析や科学計算などのライブラリが一緒になったものです)
まずはANACONDAのインストーラをダウンロードします。
CONTINUUM ANALYTICS(今回はWindows64bit環境で、PYTHON3.4のインストーラーをダウンロードしました)
それでは早速インストールしていきましょう。
インストールする場所を聞かれるくらいで、特に設定等もなくどんどん進んでいきます。
インストールが完了しました。
Pythonのプログラムを書くのにエディターが必要です。
次にエディターであるeclipseをダウンロードします。
全部入りをダウンロードしました。
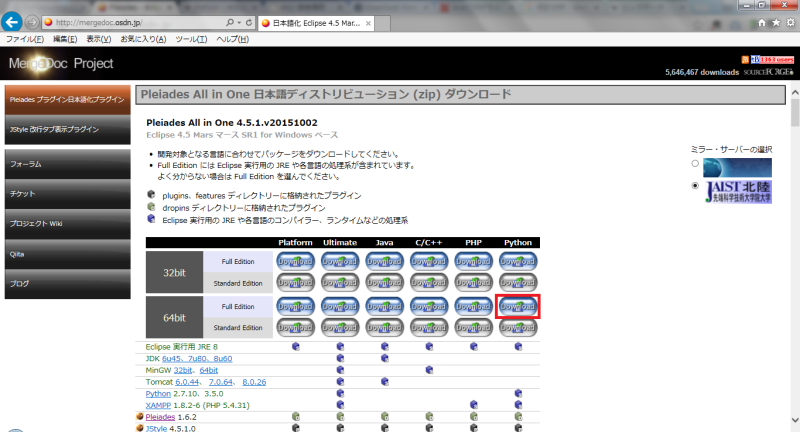
解凍して適当な場所に置いて下さい。
インストールしたAnacondaとeclipseの紐付けをします。
eclipseを起動してください。
ワークスペースは任意の場所として下さい。
さっそくeclipseを起動します。
今回はAnaconda3(Python3)をインストールしたので、Python2のチェックを外します。
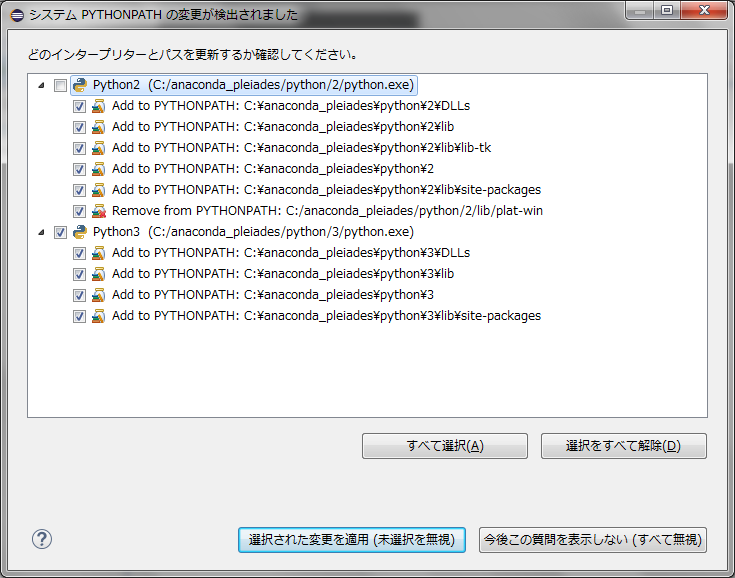
次にPythonとanacondaの設定をします。
eclipseの「ウィンドウ→設定」を選択します。
左側メニューから、「PyDev→インタープリター→Python Interpreter」を選択し、右上の「新規」を押下します。
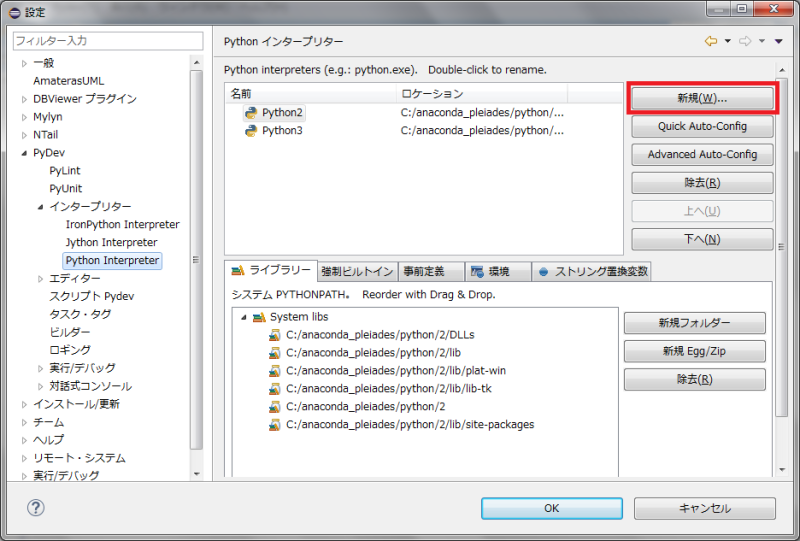
「参照」ボタンを押下し、anacondaをインストールしたフォルダから「python.exe」を選択し「OK」ボタンを押下します。
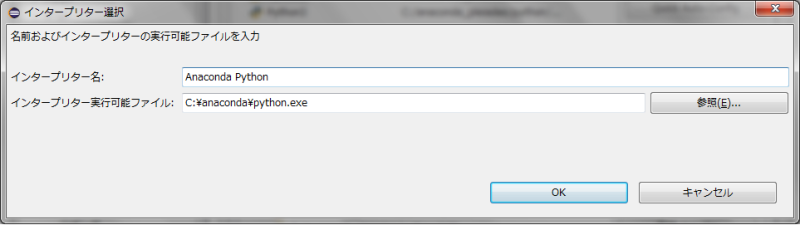
このまま「OK」ボタンを押下します。
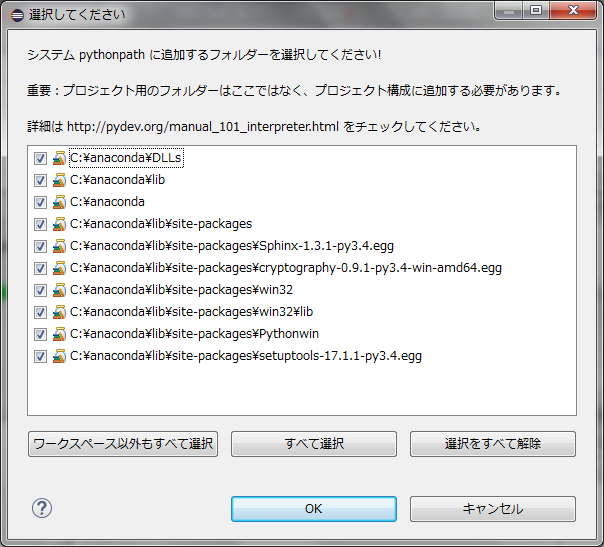
追加されました。
「上へ」ボタンを押下して、一番上に移動します。
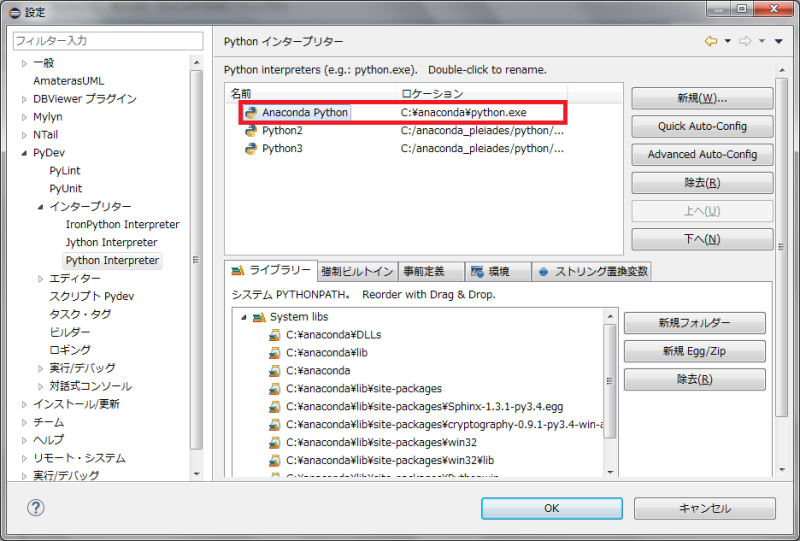
「OK」ボタンを押下し、設定完了です。
動作検証のために「test」というプロジェクトを作成し、Javaでいうところのmainクラスを作成しました。
日本語がきちんと表示されるかわからないので、日本語を出力してみようと思います。
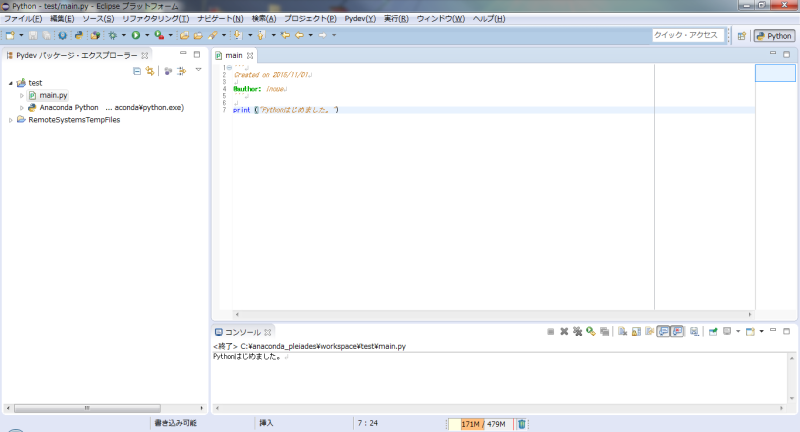
コンソールにうまく日本語が出力されました。
今回から複数回にわたってPythonを使ってビッグデータの処理をしていこうと思います。
ビッグデータをどのように活用すると、自分の欲しい結果が得られるのかを模索しながら進めていきます。
しばしお付き合い下さい。












